
How Fine-Tuned Large Language Models Prioritize Goal-Oriented Reasoning Over Comprehensive World Representations: Insights From the REPLACE Framework

Inspired by human cognitive processes, large language models (LLMs) possess an intriguing ability to interpret and represent abstract world states, which are specific snapshots of the situation or context (basically the environment) described in the text, such as the arrangement of objects or tasks in a virtual or real-world scenario. The research explores this potential by examining whether LLMs construct goal-oriented abstractions, focusing on task-relevant details, rather than capturing a comprehensive and detailed world model, i.e., a structured framework that helps the AI understand the current situation and predict how it might change.
A vital challenge in AI is determining the level of abstraction required for solving specific tasks effectively. Balancing between intricate, highly detailed world models and minimalistic abstractions is essential. More complex models can help decision-making efficiency, while excessively abstract representations may omit critical information necessary for task completion. Researchers have attempted to unravel whether LLMs can achieve this balance, particularly when tasked with understanding and acting on textual descriptions of the world. These investigations have resulted in contradictory findings, prompting the need for a more systematic approach.
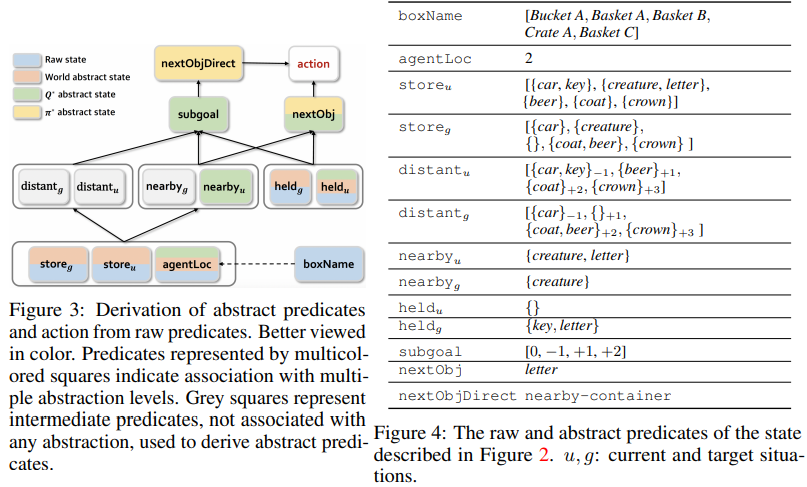
The study identifies limitations in current methods for probing LLMs. Existing research often seeks to recover the complete world state encoded in LLM representations. However, this approach must differentiate between general abstractions, which provide a broad understanding of the world, and goal-oriented abstractions, which prioritize task-specific information. For instance, some models excel in retrieving semantic relations between entities, while others struggle with tasks requiring nuanced recovery of world dynamics. These inconsistencies highlight the necessity of a framework capable of distinguishing varying levels of abstraction in LLMs.
Mila, McGill University, and Borealis AI researchers proposed a new framework grounded in state abstraction theory from reinforcement learning to address these gaps. This theory emphasizes creating simplified representations by aggregating similar states without compromising task-specific objectives. The framework was tested through a custom-designed “REPLACE” task, which challenges LLMs to manipulate objects in a textual environment to achieve a predefined goal. By varying task requirements and probing different levels of abstraction, the researchers aimed to understand whether LLMs prioritize detailed or goal-directed representations. The study also evaluated the impact of fine-tuning and advanced pre-training on the models’ abstraction capabilities.
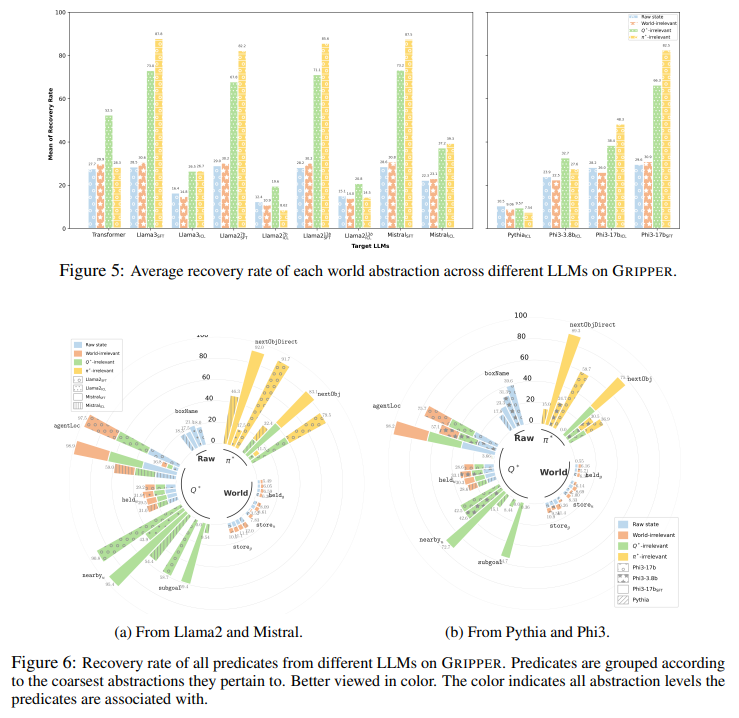
The results revealed critical insights into how LLMs process world states. Models fine-tuned for specific tasks demonstrated a strong preference for goal-oriented abstractions. For example, in the REPLACE task, fine-tuned versions of Llama2-13b and Mistral-13b achieved success rates of 88.30% and 92.15%, respectively, far surpassing their pre-trained counterparts. Also, these models exhibited optimal action selection rates of 84.02% and 87.36%, indicating their ability to prioritize task-relevant information efficiently. Notably, fine-tuned models consistently outperformed pre-trained models in preserving task-specific abstractions, demonstrating that task-oriented training enhances LLMs’ ability to prioritize actionable insights over irrelevant world details.
Advanced pre-training was found to enhance LLMs’ reasoning capabilities but primarily for task-specific objectives. For example, pre-trained models like Phi3-17b identified necessary actions well but needed help capturing broader world details. In the REPLACE task, pre-trained models demonstrated high proficiency in tracking critical relationships, such as the relative position of objects and the agent’s required next actions. However, these models had lower success rates in maintaining comprehensive world representations, such as detailed object locations across the environment. This gap underscores that while pre-training improves goal-oriented abstraction, it must fully equip models for tasks demanding holistic understanding.
An important observation from the study is how LLMs process information during task execution. Fine-tuned models largely discarded details irrelevant to completing their goals. For instance, they ignored information about static elements in the environment (e.g., naming conventions for containers) unless it directly influenced the task. This focus allowed the models to streamline decision-making processes but limited their ability to handle tasks requiring detailed world knowledge. Researchers noted that LLMs simplified object relationships to essential terms, such as determining proximity or identifying the next critical action to perform, rather than preserving intricate world dynamics.
The study’s key takeaways can be summarized below:
- LLMs, particularly those fine-tuned for specific tasks, excel in prioritizing actionable details over broader world representations. Models like Llama2-13b demonstrated an 88.30% success rate in achieving task objectives, highlighting their ability to focus on relevant information.
- Pre-training improves task-relevant reasoning but has a limited impact on understanding broader world states. For instance, Phi3-17b accurately identified critical next actions but needed help comprehensively encoding all object locations.
- Fine-tuned LLMs significantly simplify their representation of the world, discarding unnecessary information to optimize decision-making. However, this approach limits their versatility for tasks requiring a more detailed understanding of the environment.
- Fine-tuning proved critical for enhancing task success and optimality, with fine-tuned models achieving efficiency rates exceeding 84%. This improvement indicates that tailored training is necessary for maximizing LLMs’ utility in specific applications.
In conclusion, this research underscores the strengths and limitations of LLMs in representing and reasoning about the world. Fine-tuned models are adept at focusing on actionable insights, effectively abstracting away irrelevant details to achieve task-specific goals. However, they often need to capture the broader dynamics of the environment, limiting their ability to handle more complex or multifaceted tasks.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 60k+ ML SubReddit.
 [Must Attend Webinar]: ‘Transform proofs-of-concept into production-ready AI applications and agents’ (Promoted)
[Must Attend Webinar]: ‘Transform proofs-of-concept into production-ready AI applications and agents’ (Promoted)
The post How Fine-Tuned Large Language Models Prioritize Goal-Oriented Reasoning Over Comprehensive World Representations: Insights From the REPLACE Framework appeared first on MarkTechPost.
Leave a Comment